
OpenAI 推出了强化微调 (RFT),这是一种模型定制技术,可让企业为复杂的特定领域任务构建高度专业化的 AI 模型。通过使用 RFT,用户可以训练模型,使其像法律、医学、金融和工程等领域的专家一样进行推理 – 利用 OpenAI 用于开发自己的前沿模型的相同技术。
要点:
强化微调 允许组织使用少至十几个示例来训练专家 AI 模型,使用强化学习来改进推理。
OpenAI 的 alpha 程序 现已推出,计划于 2025 年初公开发布。
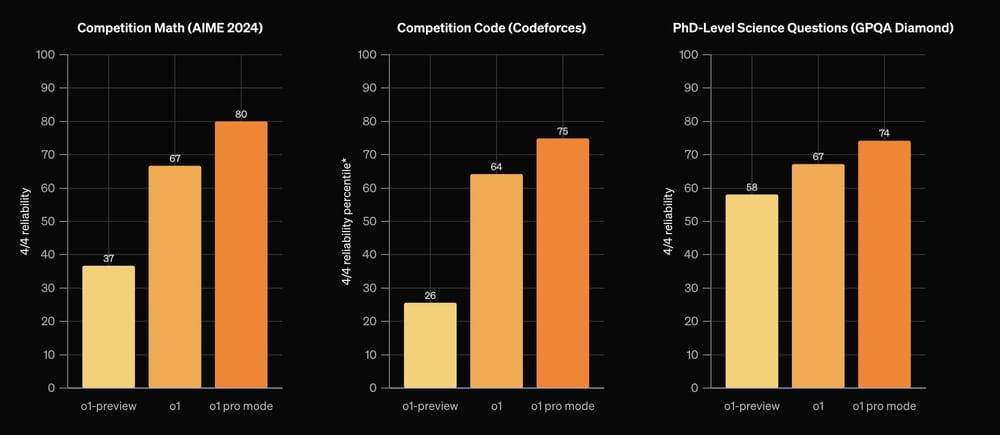
RFT 在法律、医疗保健和工程等领域取得了成功,具有先进的、特定任务的能力。
该技术不同于监督微调,它教模型如何推理和解决问题,而不是简单地模仿输入数据。
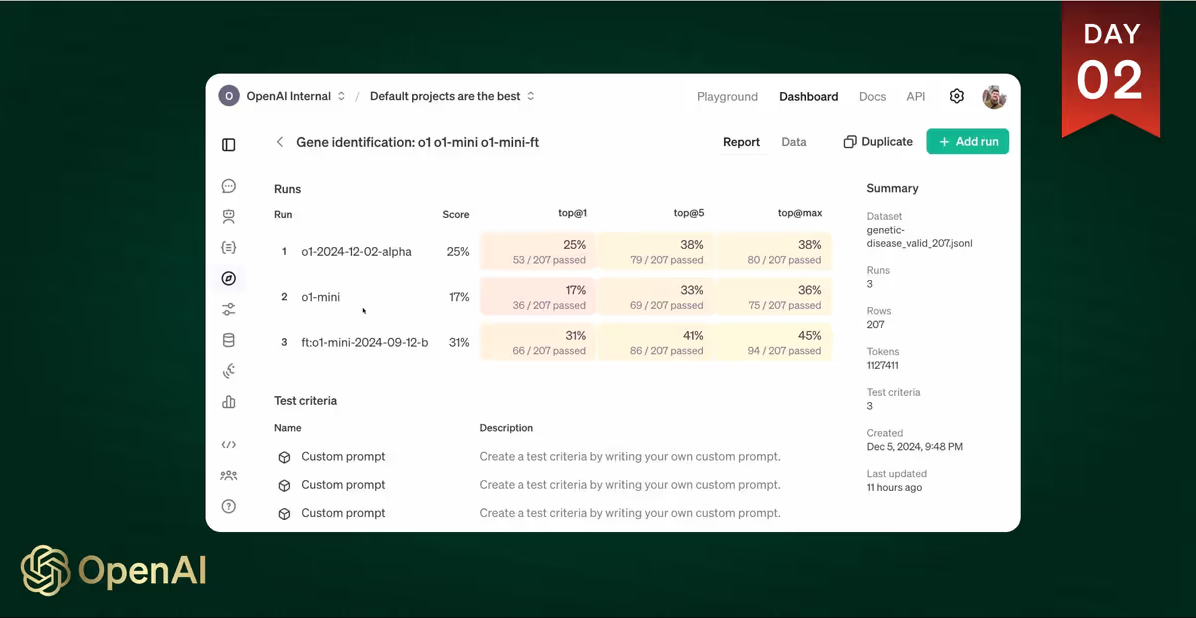
在直播中,伯克利实验室的计算生物学家 Justin Reese 展示了 RFT 如何提高模型识别罕见疾病遗传原因的能力。“评估罕见疾病有点困难,因为你必须具备两样东西:关于医学方面的专业领域知识和对生物医学数据的系统推理,”Reese 在演讲中指出。
重要性: RFT 是 AI 定制化方面的一大进步,它使企业能够训练模型以完成精确的、特定领域的任务。与传统的微调不同,RFT 提高了模型推理问题的能力,而不仅仅是复制模式。这一进步可能会重新定义企业如何在需要深厚专业知识的领域使用 AI。
工作原理: RFT 利用强化学习来引导模型进行更好的推理。用户提供数据集和评分标准(称为评分者)来对模型输出进行评分。这些分数指导训练过程,改进模型的推理能力,以有效处理复杂、高风险的任务。
该技术的有效性在演示中尤为明显,微调版 GPT-4 mini 在特定任务上的表现优于基础 GPT-4 模型。微调模型在第一次尝试识别正确基因时的准确率为 31%,而基础模型的准确率为 25%。
谁将受益: RFT 非常适合那些对准确性要求很高的行业,例如法律分析、科学研究和财务预测。OpenAI 已经与汤森路透等组织合作开发法律 AI 工具,展示了在专家驱动领域转变工作流程的潜力。
展望未来: OpenAI 已启动RFT 的alpha 计划,鼓励企业、大学和研究机构申请。参与者将获得 RFT API 的早期访问权限,并在 2025 年初全面发布之前提供反馈以完善该工具。
强化微调有望使尖端人工智能的普及,使组织能够构建定制解决方案来应对其独特挑战。凭借使用最少数据调整模型的能力,强化微调有望成为跨行业创新的基石。