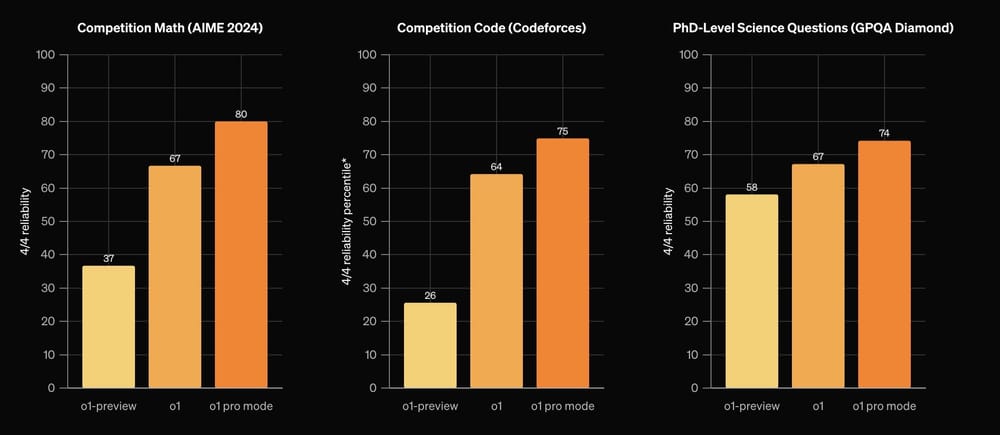
近期一场公开讲座吸引了业内人士的广泛关注,一位曾在 OpenAI 任职的高管向大家详细介绍了 ChatGPT 后训练阶段的核心策略。讲座现场展示的 PPT 内容涉及模型调优、数据清洗、参数微调以及安全防护等关键环节,利用详实数据和实际案例为听众呈现了后训练过程中的各个步骤。高管详细描述了如何通过大规模数据采集和严格的样本筛选,建立起一个高质量的数据集。系统对原始数据进行分类整理和标注加工,通过多次迭代调整模型参数,实现对语言理解与生成能力的持续优化。演示中提到,后训练策略的关键在于精细化管理数据和不断校正模型输出,使得生成的文本更贴近真实语境和用户需求。
讲解者特别强调了在数据预处理过程中,对噪音数据进行剔除的重要性。大量样本经过层层筛选,保证输入模型的都是高质量信息,促使模型在后续调优中更快收敛,提升整体表现。此次公开分享不仅涉及技术原理,还对实验结果进行了直观展示,图表清晰呈现了不同策略对模型性能的影响。现场观众通过互动提问,对参数调整、模型校验和安全机制构建等方面展开了深入讨论,大家普遍认为这种公开分享有助于推动整个行业技术水平的提升。技术人员在了解了该后训练流程后,纷纷表示将结合自身需求探索更多可行的应用方案,力求在各自领域中实现模型性能的突破。
延伸阅读:
如何用 ChatGPT 4.0 生成精准的 B2B 营销内容
公开材料中还展示了模型在处理敏感信息时采用的安全防护措施。高管指出,在后训练阶段,除了关注性能提升,保障模型输出的规范性和客观性也十分重要。相关措施包括针对敏感词汇的过滤、异常行为的监控以及多维度的数据比对,确保模型不会生成不适宜内容。该技术分享为技术研发人员提供了一个全新的视角,也为行业内的学术交流搭建了平台。大家在聆听过程中纷纷记录下关键数据和流程图,认为这种开放透明的交流方式有助于形成更加健全的技术生态系统。公开分享结束后,参与者纷纷表示收获颇丰,对后训练策略有了更为全面和深入的认识。
这场讲座为业内提供了宝贵的实战经验,推动了技术标准的不断完善。与会人员普遍认为,这种实践探索对于提升人工智能模型在实际应用中的表现具有积极意义,必将引领更多团队在数据驱动和算法优化方面取得突破,促进人工智能技术的长足发展。