评估大型语言模型如ChatGPT的实际应用效果,并非易事。单纯的准确率和流畅度指标,无法全面反映其在真实场景中的价值。我们需要从多个维度,结合定量和定性分析,才能获得更客观、全面的评价。
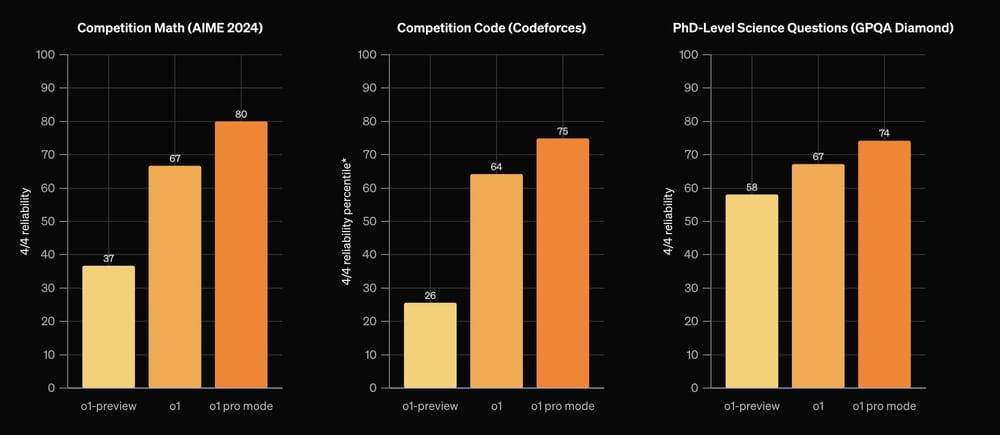
首先,任务完成度是关键指标。这需要明确ChatGPT所承担的任务,并根据预设目标评估其完成情况。例如,如果任务是撰写一篇营销文案,则需要考量文案的吸引力、说服力以及是否符合目标受众的需求。而如果是代码生成,则需要评估代码的正确性、效率和可维护性。这部分的评估往往需要人工参与,并制定相应的评分标准。
其次,效率和成本是不可忽视的因素。ChatGPT能否显著提升工作效率,降低运营成本?例如,它能否替代部分人工客服,减少等待时间,提升客户满意度?又或者它能否加速软件开发流程,缩短项目周期?这些都需要通过实际数据进行量化分析。成本考量则包括模型的训练成本、部署成本以及使用成本等。
此外,用户体验至关重要。ChatGPT的易用性、交互性以及输出内容的可用性都会影响用户满意度。这可以通过用户问卷调查、用户访谈以及行为数据分析等方式来进行评估。例如,用户反馈中频繁出现的负面评价,可能反映出模型在特定场景下的不足,需要改进。
更进一步,需要考虑ChatGPT的安全性和伦理问题。模型是否会产生有害、歧视性或不准确的内容?如何确保模型的输出符合伦理规范和法律法规?这些都是需要深入研究和评估的方面。 有效的评估需要建立完善的监控机制,及时发现并解决潜在风险。
最终,对ChatGPT实际应用效果的衡量,需要结合具体的应用场景,选择合适的评估指标和方法,并持续跟踪和改进。 只有这样,才能真正了解其优势和局限,并最大限度地发挥其价值。